
今回は、requests や BeautifulSoup を使った本格的なスクレイピングではなく、pandas の read_html を使っています。
HTML構造を細かく解析する必要がないため、Python初心者が「まずデータ取得を体験する」には適した方法です。
・pandas の read_html を使ってWeb上の表データを取得する方法
・取得したデータを整形してExcelに保存する流れ
・スクレイピング未経験でも「データ取得の一連の流れ」を体験する方法
この方法が向いている人・向いていない人
この方法は、Webページ上に「表」として公開されているデータを手軽に取得したい場合に向いています。
一方で、JavaScriptで動的に生成されるデータや、ログインが必要なページには対応できません。
まずは「Pythonでデータを取って加工する流れ」を体験したい方に適した方法です。
概要
このプログラムは、Pythonを使用してYahooファイナンスから優良高配当株のデータ(いわゆるにわとりリスト)を取得し、Excelファイルに書き出すものです。プログラムは5ページ分のデータを取得し、各ページのデータを結合して最終的に1つのデータフレームにまとめます。また、特殊な銘柄名称(例:4℃ホールディングス)も正しく処理できるようにしています。
使用するライブラリ・バージョン等
- Python 3.11.1
- pandas 2.0.3
- re: (Pythonの標準ライブラリ)
プログラムのコード
以下にプログラムの完全なコードを示します。
import pandas as pd
import re
def mks_re(x):
mks_d = re.search(r'\d{4,}', x) # 銘柄コードが4桁以上の数字であると仮定
if mks_d:
dks_c = mks_d.group() # コード
dks_m = x[0:mks_d.start()].strip() # 名称
dks_s = x[mks_d.end():].strip() # 市場
return dks_m, dks_c, dks_s
else:
return x, None, None # コードが見つからない場合、名称だけを返す
def bunkatu(df):
df[['名称', 'コード', '市場']] = df['名称・コード・市場'].apply(lambda x: pd.Series(mks_re(x)))
dfa = pd.DataFrame()
for p in range(1, 6):
dfw = pd.DataFrame()
url_kh = 'https://finance.yahoo.co.jp/stocks/screening/highdividend' + '?page=' + str(p) # 優良高配当株 1~5ページ
dfs = pd.read_html(url_kh) # データフレームの準備
df = dfs[0] # 1つ目のテーブルを取得
bunkatu(df) # 繋がった文字列を分割
dfw = df.reindex(columns=['名称', 'コード', '市場', '配当利回り', 'PER', 'PBR', 'ROE', '自己資本比率', '時価総額', '最低購入代金'])
dfa = pd.concat([dfa, dfw], ignore_index=True) # 1ページごとに結合
dfa.to_excel('優良高配当株.xlsx') # エクセルへ書き出し
プログラムの説明
必要なライブラリのインポート:
import pandas as pd
import re銘柄名・コード・市場を分解する処理
テキストから銘柄コード、名称、市場を抽出する正規表現を使用します。銘柄コードは通常4桁以上の数字であると仮定し、名称や市場部分の前後のスペースを削除します。
def mks_re(x):
mks_d = re.search(r'\d{4,}', x) # 銘柄コードが4桁以上の数字であると仮定
if mks_d:
dks_c = mks_d.group() # コード
dks_m = x[0:mks_d.start()].strip() # 名称
dks_s = x[mks_d.end():].strip() # 市場
return dks_m, dks_c, dks_s
else:
return x, None, None # コードが見つからない場合、名称だけを返す取得した表データを列ごとに整理する処理
テキストを名称、コード、市場に分割し、新しい列に格納します。
def bunkatu(df):
df[['名称', 'コード', '市場']] = df['名称・コード・市場'].apply(lambda x: pd.Series(mks_re(x)))メイン処理:
5ページ分のデータを取得し、※データフレームに結合します。
dfa = pd.DataFrame()
for p in range(1, 6):
dfw = pd.DataFrame()
# 優良高配当株 1~5ページ
url_kh = 'https://finance.yahoo.co.jp/stocks/screening/highdividend' + '?page=' + str(p)
dfs = pd.read_html(url_kh) # データフレームの準備
df = dfs[0] # 1つ目のテーブルを取得
bunkatu(df) # 繋がった文字列を分割
dfw = df.reindex(columns=['名称', 'コード', '市場', '配当利回り', 'PER', 'PBR', 'ROE', '自己資本比率', '時価総額', '最低購入代金'])
dfa = pd.concat([dfa, dfw], ignore_index=True) # 1ページごとに結合
dfa.to_excel('優良高配当株.xlsx') # エクセルへ書き出しエクセルに書き出した結果
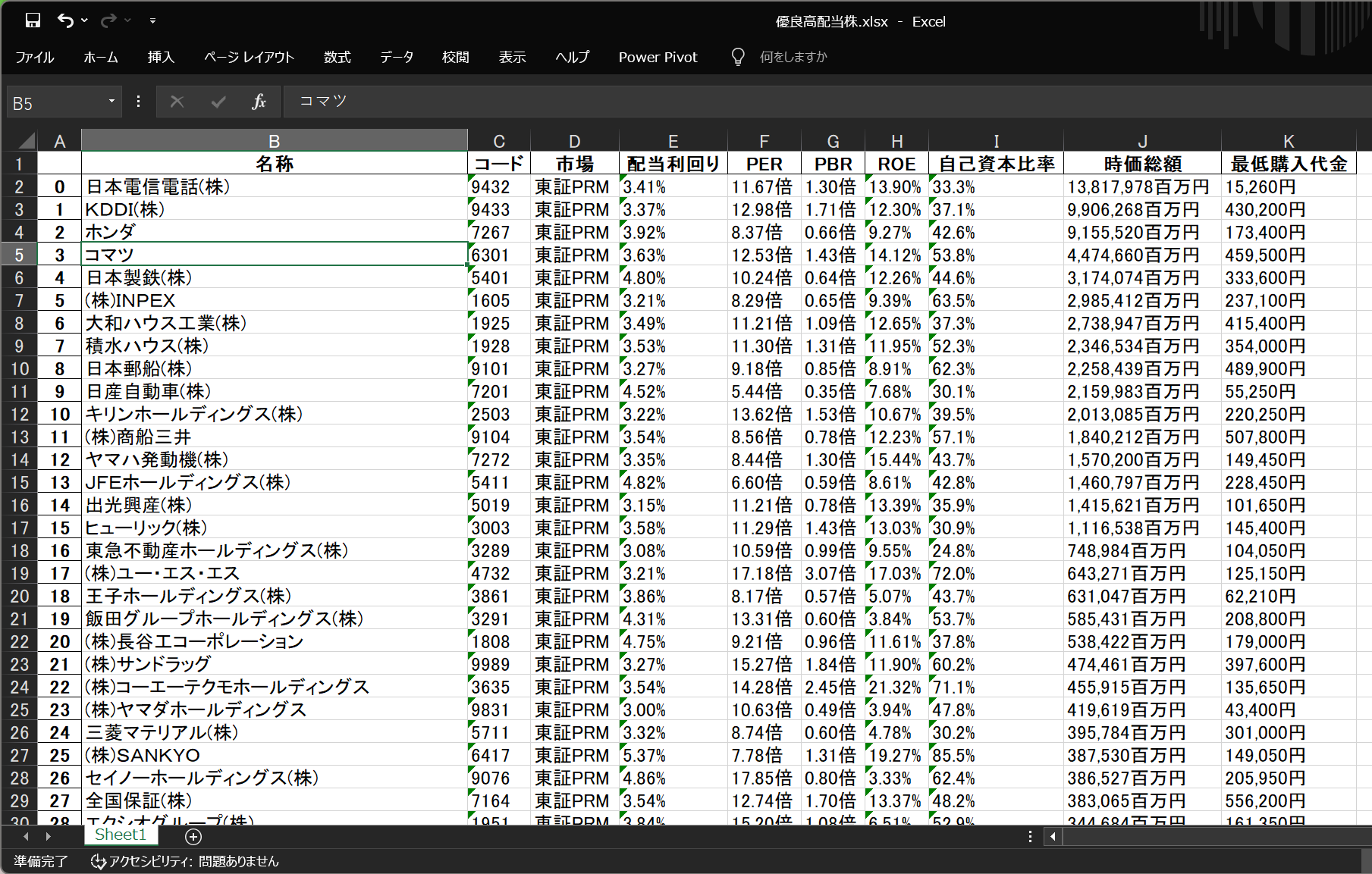
このように、複数ページ分のデータが1つのExcelファイルにまとめて出力されます。
まとめ
今回は、pandas の read_html を使って、高配当株のデータを取得し、Excelにまとめる方法を紹介しました。
本格的なスクレイピングではありませんが、Pythonで「データ取得 → 加工 → 保存」という一連の流れを体験するには、ちょうど良い題材だと感じています。
今後は、取得条件を絞ったり、他の指標を追加したりすることで、Python学習の練習素材として発展させることもできます。
まずはこのように、pandasを使って「取得・加工・保存」の流れを体験することが大切だと感じました。
今後は、条件での絞り込みや指標の追加なども試してみたいと思います。
※データフレームとは
Pandas DataFrame とは、表形式のデータを表示、操作する方法の一つです。二次元のデータ構造で、データを行と列に整理してテーブルとして表示します。
pandas DataFrame を使用すると、様々な形式のデータを様々なソースから取り込むことができます。例えば、 pandas の内容をインポートできるのと同時に、 NumPy の配列をインポートすることができます。



